The OERu Blog Feed Finder
One of the distributed tools that the OERu makes available as part of its open source distributed digital learning environment is WEnotes. I've described what it is and how it works previously. One of the most powerful distributed tools has also been the most complicated to achieve: the ability for learners to complete assignments and reflect on their learning journeys on their own blogs, tagging posts with relevant OERu course ids (e.g. lida101 - see the Learning in a Digital Age 101 course feed for example) and then having our blog feed scanner:
- know to look at the learner's blog in a timely manner,
- identify the newly published appropriate blog post (i.e. with the relevant tag), and
- create a WEnotes message with a reference to the blog post
for the other learners participating in the course to see.
There are a lot of moving parts in achieving this ambition, but the most unexpectedly difficult (from my perspective as a technologist) was solving the first problem: knowing how to find the learner blog feeds to monitor!
The mysterious blog feed
It turns out few people who use the web, even those who blog, are familiar with "feeds". A "feed" is a web accessible file, adhering to a well-known and publicly defined "open standard" machine readable format, which summarises and references (links to), the content on a website, in this case a blog. Most blog platforms enable them right out-of-the-box, by default. This fact isn't widely appreciated, even among active bloggers!
If you haven't seen a feed, here're some examples and an explanation of the two most common types: RSS (which stands for "Really Simple Syndication") and Atom, both of which support "tagging" content.
When we (here at the OER Foundation) first looked into offering the monitoring of learner (or educator) blogs for suitably tagged posts to include in course interaction feeds, I thought it would be a simple process of allowing learners to nominate a "Blog Feed URL" when they registered an account on our Course Site. I was quite mistaken.
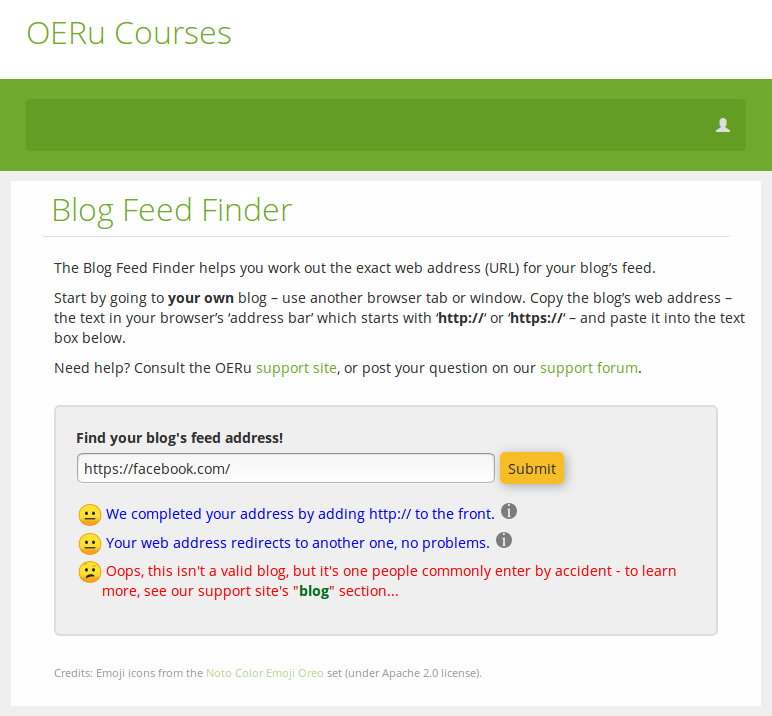
Over the course of six or so months after we made a "Blog Feed URL" field available in learner profiles, entered during the registration process, we had perhaps a hundred or so learners nominate a URL. (N.B. our model allows a learner to nominate a different blog feed URL for each course in which they're participating, allowing for the possibility that they might create a new blog site for each course. Naturally, they can nominate the same blog URL for multiple courses) Of those, perhaps one in 50 was an actual valid blog feed URL. Most were not even valid blog addresses. The most common entries were either facebook.com, google.com, a wikieducator.org user profile, or the course's own url - none of which are blogs, much less blog feeds. So this was useful market research: the market does not, in general, know what a blog is or what its feed might be, if it has one.
Among other problems this creates is the fact that our automated feed monitoring code could not effectively sift the wheat from the chaff to find valid blog feeds to monitor. Clearly, a different approach was required.
Back to the drawing board
Turns out that if a learner has a blog, they generally know its web address. If provided clear instructions, they can fairly reliably go to it, and copy and paste the URL into a text field. So I decided to use this as a starting point for creating our "Blog Feed Finder" - a simple tool that helps us side step the issue of requiring a learner to find their blog feed URL - by finding it for them. Our approach was to provide a clear, well documented interface that embraces "elaboration theory", providing enough information at a glance to guide a learner, but offers further information to those who want to understand more.
Here's what it looks like:
I'll copy in the URL of this very blog (and I won't even bother with the "https://" that appears at the start of it):
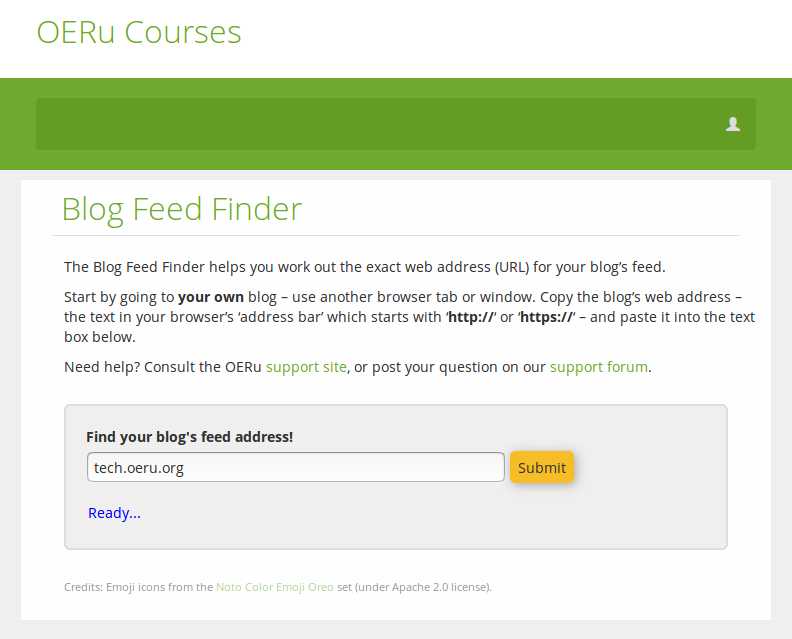
After a few seconds of behind-the-scenes whirring and grinding...
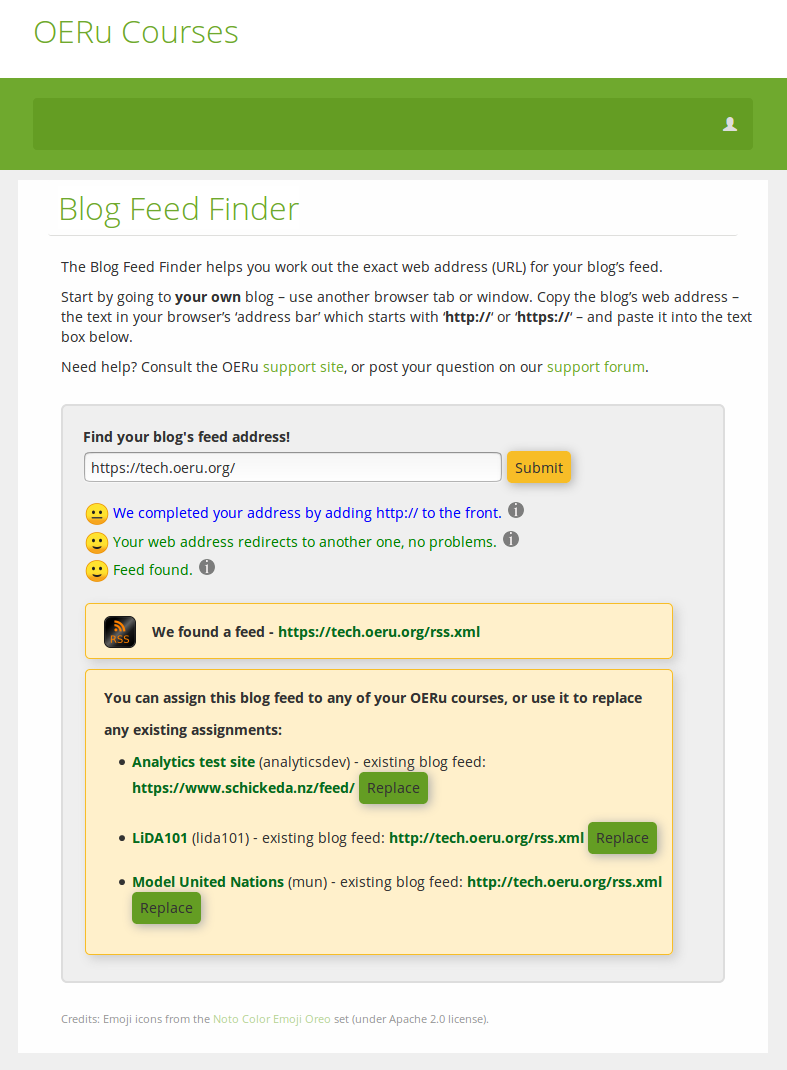
If we want to know more about what the BFF had to do to find that blog feed, we can review its output, and even ask for more information by hovering over the info icons, fo example:
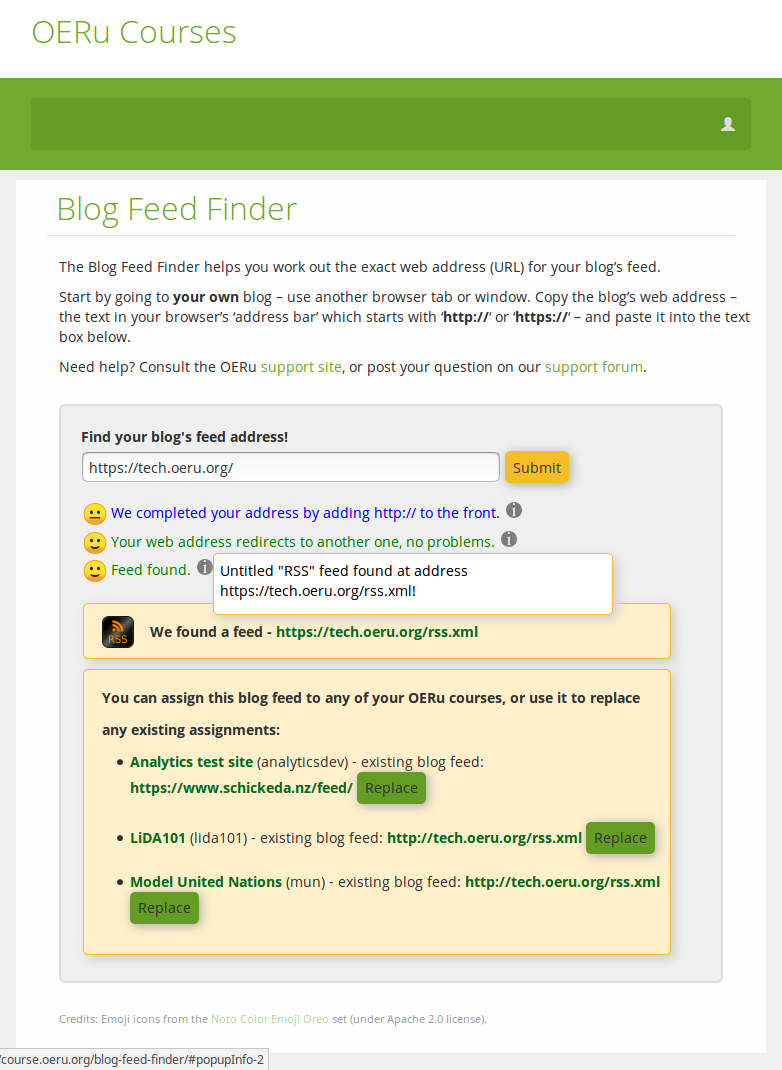
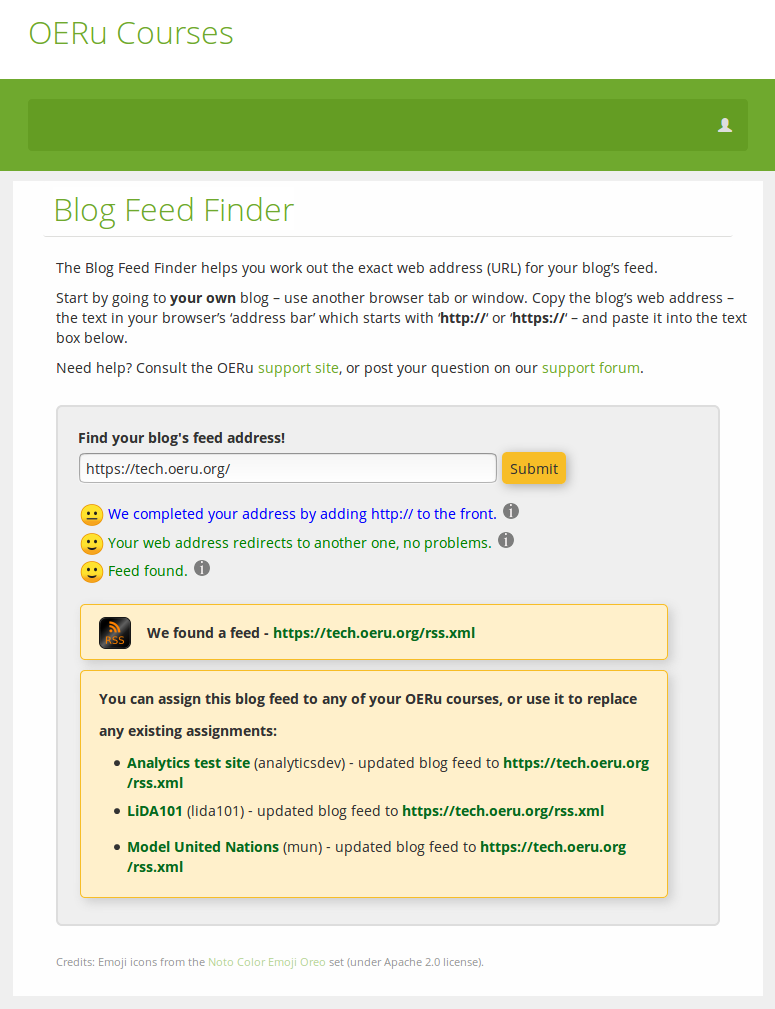
And having found a feed, we can now update any of the courses for which we're registered to use that feed as the designated "feed to scan periodically" for blog posts tagged with the relevant course code (in brackets next to each course title, e.g. analyticsdev, lida101, mun).
Here's what it looks like after I've replaced all of my blog feed associations with the new feed URL:
And, what if, instead of tech.oeru.org, I'd mistakenly entered a URL like one of those I mentioned above? Here's how the BFF responds if someone enters, say, Facebook.com as their blog URL:
Try it now, or adapt it! It's free (and open source)
Of course, you can try it yourself right now without even needing to log in, although you get additional functionality if you're logged in and enrolled in one or more courses, like the ability to assign blog feed URLs to any courses in which you're enrolled.
Even though we're only on our first iteration of it (any software developer will tell you: no software application is ever finished) our Blog Feed Finder (BFF for short) has also been assessed by others in the online learning realm, who have given it a good going over and their seal of approval.
If anyone is curious about how it works, the entire source code is available under the terms of the GNU Affero General Public License (same as what's used by the Linux kernel, WordPress, Drupal, MediaWiki, and thousands of other well know free and open source projects) to make its review and reuse convenient and reliable!
OERu Blog Scanner is Go!
As of a few weeks ago, following the introduction of the BFF (and a bit of manual tidy-up of previously entered blog feed URL where OERu administrators used the BFF to find legitimate feed URLs where-ever possible) we now have a working scan which periodically checks all registered learner blog feeds and, if a suitably tagged post is found on any of them, incorporates a link to the post in the relevant course feed!
The course interaction feed (also linked above) includes some posts with a "blog" designator, which indicates they are references to blog posts which have been scanned by our WEnotes blog scanner (which is a different piece of software).
Loose Ends
As with any first iteration software release, there are quite a few known issues (a whole itemised, prioritised list, actually) we'd like to address for the next release. The first among them in the BFF's case is making the interface properly "responsive" (i.e. friendly for mobile device users)... At present, it doesn't do very well at that.
If you have a go with the BFF and run into trouble related to the software itself, we encourage you to let us know in the project's Issue Queue.
Final note: we will be moving our source code repositories to a properly open source code repository (our own Gitlab instance) in the coming weeks, so you may find you're being redirected from Github to a different site. Please don't be alarmed! It's by design.
Add new comment